
この記事は、ベイズ塾Advent Calender2020 17日目の記事です。
本記事では、全くStanもRも使えない状態から2年くらい勉強してきました。この機会に(?)これまでどんな感じでベイズ統計モデリングを使って研究してきたかまとめました。
自分の研究とベイズ統計モデリング
- 初期: 階層モデルでモデル内のパラメータを推定して個人変数として使用
- 中期: すでにあるモデル同士を自分でとったデータに当てはめて比較
- 今: オリジナルのモデル同士を自分でとったデータに当てはめて比較
初期: 階層モデルでモデル内のパラメータを推定して個人変数として使用
卒論研究で、個人のもつ遅延価値割引率とある変数の相関を見る研究をしました。遅延価値割引とは、ある財をもらえるまでの時間が長くなればなるほどその財の価値が主観的に下がっていく現象です。財をもらえるまでの時間と主観的な価値の関係は関数で表されます。遅延価値割引の程度は人によって異なります。たとえば同じ「1か月後にもらえる10000円」でも、人によって8000円くらいに感じられていたり5000円くらいに感じられていたりするわけです。その個人差を表す値が、遅延価値割引率です。
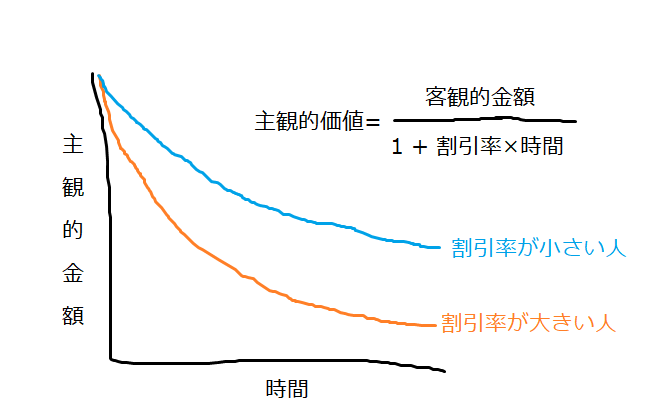
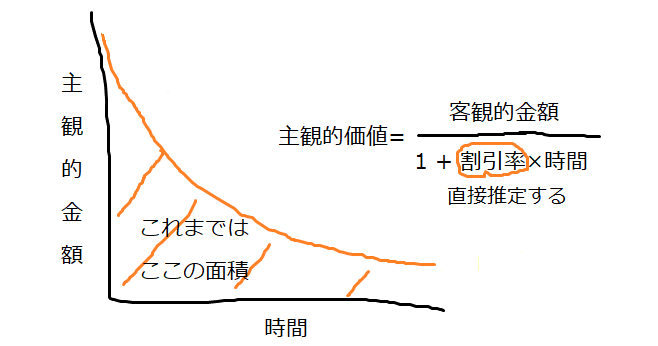
個人のもつ割引率は従来、実験課題のデータを使って主観的金額と時間の関数を描き、その下の面積を積分で求めることで算出されていました。しかし、階層モデル (モデル内のパラメータを個人ごとに推定できる) を使えば、個人ごとに割引率をデータから直接推定することができます。この値を変数として使って研究しました。
階層モデルは、ベイズ統計モデリングによってパラメーターを推定することが容易になったモデルのひとつである。階層モデルでは、パラメーター自体に加えてパラメーターの事前分布にも正規分布やコーシー分布などの確率分布を設定することでパラメーターに階層性をもたせます。階層モデルの利点は、個人間やグループ間での効果の差といったモデルの複雑さを表現しながら推定精度を上げることができる点です。
ようは、
モデルの中のパラメータを個人ごとに推定して個人変数として使いたい
→ 個人ごとのパラメータ推定には階層モデルが効率的
→ 階層モデルを解くのにベイズ統計モデリングが便利
→ RとStanを使えばそれができる
のです。
追記: この一連の流れの参考になる書籍としては、以下が挙げられます。
- 『StanとRでベイズ統計モデリング』(通称あひる本) Chapter8
Stanの入門書としてまず勧められる本 - 『たのしいベイズ統計モデリング―事例で拓く研究のフロンティア』
遅延価値割引は6章。階層モデルによる個人差の表現が至る章に登場するし、どの事例もたいへんおもしろい - 『社会科学のためのベイズ統計モデリング』
遅延価値割引モデルは9章
中期: すでにあるモデル同士をデータに当てはめて比較
大学院に入ると、自分でとったデータで、すでにあるモデル同士を比較する研究をするようになりました。(例えば水野・清水, 2020)
同じ現象、例えば上で挙げた遅延価値割引現象であっても、主観的金額と時間を表すおもな関数が二つ提案されています。二つの関数はそれぞれ、どのように時間によって主観的価値が下がるかのメカニズムを表します。それら同士の比較をするということは、メカニズム1とメカニズム2のどちらが妥当であるかデータで決着をつけるということです。
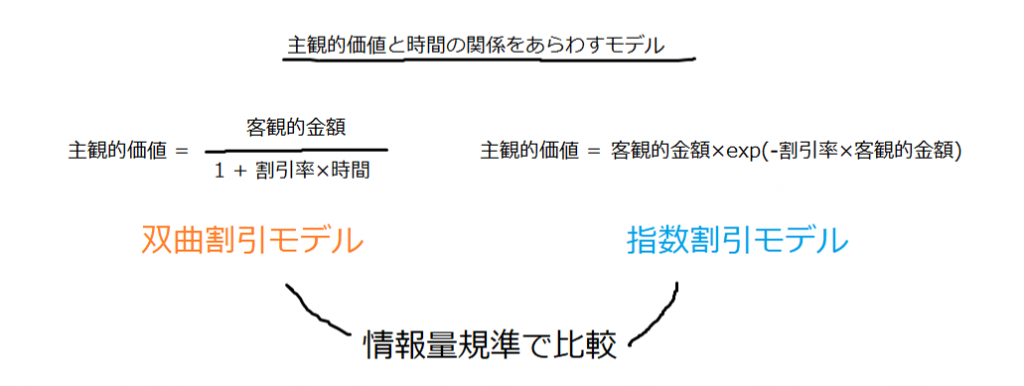
モデル同士の比較を行うためには、客観的な指標が必要です。そのひとつが対数周辺尤度です。周辺尤度とは、パラメータがとりうるすべての値について考慮したときの手元のデータに対するモデルの持つ平均的な予測力のことです。その値が大きいモデルほどデータを説明するうえで相対的にふさわしいといえます (岡田, 2018)。周辺尤度の算出が、MCMCを使うと簡単にできます。
ようは、
複数のモデル (メカニズム) の中でどれがよいか、データを使って比較したい
→ そのためにはモデルを評価する客観的な指標が必要
→ その指標の算出にMCMCが便利
→ RとStanを使えばそれができる
のです。
モデル比較について参考になる書籍としては、以下が挙げられます。
- 『Pythonによるベイズ統計モデリング』6章
RやStanの話ではないが、モデル比較について詳しく書かれている - 『行動データの計算論モデリング―強化学習モデルを例として―』
今: オリジナルのモデル同士を比較
今は、モデル (メカニズム) 自体オリジナルのものを用意して、それら同士、またオリジナルのモデルと既存のモデルの比較をしたりしています。
モデルの作り方…もいつか記事を書きたいと思っています。
「モデルを作る」ことの参考になる書籍としては、以下が挙げられます。
最初なにがわからなかったか
学部4年生 (今修士2年なので2年前) からベイズ統計モデリングの勉強をはじめたのですが、最初はまっっったく何もわかりませんでした。ベイズ塾合宿にも参加させてもらったのですが、発表された内容がなにもわからずに自分はアホなのではないかと暗くなりながら博多ラーメンを食べてました。
何がわからなくてわからなかったのか、今思えば
- ベイズ統計モデリングでなにができるのか (そもそも)
- オブジェクトの格納などのRの超基本 (パソコンやプログラミングの常識)
でした。それらがわかってから一気に理解が進みました。
べイズ統計モデリングでなにができるのか
複雑なモデルの中のパラメータを個人ごとに推定して個人変数として使いたい
→ 個人ごとのパラメータ推定には階層モデルが効率的
→ 階層モデルを解くのにベイズ統計モデリングが必要
→ RとStanを使えばそれができる
ところが一番腑に落ちました。「階層モデル難しくない?そこが一番腑に落ちたなんて珍しいね」と言われます。もしかしたら自分が心理学 (個人変数を測定するのが当たり前の分野) の専攻だからかもしれません。
コンピュータやRの超基本
ベイズ統計モデリングに興味がある人は元々プログラミングやコンピュータに強い傾向にある気がします (なんとなく)。
私は最初どちらにも詳しくなかったので、みんなが当たり前に言っている用語を知らなかったり、同じ階層にファイルを置いていなくてエラーを出しまくったりしました。なので「Cドライブとは」とか「ディレクトリとは」とか「オブジェクトとは」から勉強しました。具体的には、みんなが当たり前に言っているけど自分は知らない言葉が出てきたらすぐに調べて覚えるようにしました。そういうコンピュータの常識がわかるまでは、みどり本のコードを実行するのさえ難しかったです。
みどり本とは、久保拓弥先生の『データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC』のことです。めちゃくちゃいい本です。統計の基礎について学べるのは勿論、私はこの本の勉強でRが使えるようになりました。
Rの「オブジェクトの格納」の概念が理解できていなかったのですが、そこがみどり本で詳しく解説されていたように思います。
おわりに
これまでの研究とベイズ統計モデリングについてざっと書きました。お読みいただきありがとうございました。これからも勉強続けます。
紹介した書籍は現時点で私が読んだものだけなので、他にも勉強になる本をご存じの方もいらっしゃると存じます。コメント等で教えていただけると喜びます。